Adding Grammar Checking To Gtk4's TextView
Search for a command to run...
No comments yet. Be the first to comment.
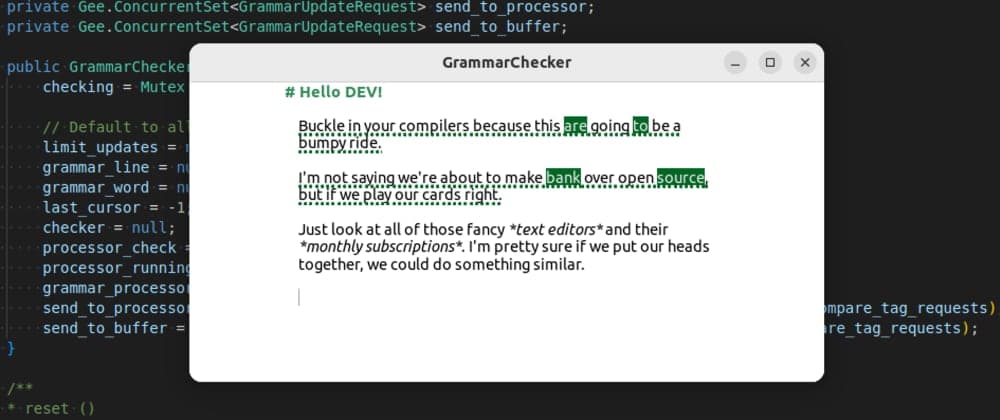
Buckle in your compilers because this is going to be a bumpy ride.
If I'm being honest, too many text editors are focused on the eye candy. How many times have you heard "We don't need Word Processors anymore; we have markdown"? Then you look in the comments section, and everyone's poking fun at grammatical errors.
We abandoned the word processor, and now we're running around unhinged and unchecked.
The world doesn't have to be that way. We can do better. We can do it for free.

The Word Processor did not abandon us. AbiWord's Link Grammar Parser is free, open source, and actively maintained. There's bindings for Java, Node.js, Perl, Python, and Vala.
Today we're going to use some Vala, GTK4, GtkSourceView5, and the Link Grammar Parser. Let's make like the Hulk and smash them together.
I'm on Ubuntu 22.04. In order to grab all of the stuff listed above, we can run:
sudo apt install build-essential valac libgtk-4-dev libgtksourceview-5-dev liblink-grammar-dev meson ninja-build
The directory structure I used for the project was:
├── meson.build
├── src
│ ├── Application.vala
│ ├── Functions.vala
│ ├── GrammarChecker.vala
│ └── Markdown.vala
└── vapi
└── linkgrammar.vapi
We have to download the linkgrammar.vapi into the vapi directory. You can clone the code for this tutorial from github.com/TwiRp/gtk4-textview-grammar.
To use the VAPI, we have to tell the compiler where to find it.
project('grammarview', ['vala', 'c'],
version: '0.0.1'
)
# Find linkgrammar (under library name)
cc = meson.get_compiler('c')
linkgrammar = cc.find_library('liblink-grammar', required: false)
# If we can't find the library, double check without the "lib" prefix.
if linkgrammar.found() == false
cc = meson.get_compiler('c')
linkgrammar = cc.find_library('link-grammar', required: true)
endif
# Define our dependencies
example_deps = [ dependency('gtk4'), dependency('gtksourceview-5'), dependency('gee-0.8'), linkgrammar ]
# Tell the compiler where our custom Vala Bindings are
add_project_arguments(['--vapidir', join_paths(meson.current_source_dir(), 'vapi')], language: 'vala')
# Define our executable and its sources
executable(
'grammarview',
'src/Application.vala',
'src/GrammarChecker.vala',
'src/Functions.vala',
'src/Markdown.vala',
dependencies: example_deps,
vala_args: [
meson.source_root() + '/vapi/linkgrammar.vapi'
],
install: false
)
There's some puzzle pieces we have to define and put together. We need to be able to call into the link-grammar library. We also need to extract sentences from a Gtk.TextView. Somehow, we have to update the text view at a non-obnoxious rate.
Link-Grammar works by performing some part of speech tagging and finding legitimate connections between the words. When a connection can't be formed, it can be considered a grammatical error.
The library allows us to specify constraints when parsing sentences along with choosing a dictionary.
//
// Class for running `link-parser` with timing constraints
//
public class GrammarThinking : GLib.Object {
// Link Grammar State
private ParseOptions options;
private Dictionary dictionary;
private string language;
public GrammarThinking () {
options = new ParseOptions ();
options.set_max_null_count (150); // Max Number of null Links allow
options.set_verbosity (0); // Silent Mode
options.set_linkage_limit (150); // Max Number of Links
options.set_max_parse_time (2); // 2 Seconds per sentence
check_language_settings ();
}
public void check_language_settings () {
// Get user's locale
var locale = Intl.setlocale ();
if (locale != null) {
if (locale.length >= 2) {
// Attempt to set language dictionary
language = locale.substring (0, 2);
dictionary = new Dictionary (language);
if (dictionary == null) {
language = "";
}
}
}
}
In this code, we limit each sentence to 2 seconds of parsing and 150 links. We also read the configured locale settings and attempt to set the dictionary to match.
For checking sentences, we can write create a sentence object and ask the Parser to parse it.
// Check grammar in a sentence
public bool sentence_check_ex (string sentence, out string suggestion, Gee.List<string>? problem_words = null) {
suggestion = "";
if (language == "" || dictionary == null) {
return true;
}
bool error_free = true;
string check_sentence = strip_markdown (sentence).chug ().chomp ();
// If it looks like we'd be noisy for HTML or random syntax
if (check_sentence.contains ("[") || check_sentence.contains ("]") ||
sentence.contains ("<") || sentence.contains (">") || sentence.has_prefix ("!") ||
sentence.replace ("-", "").chug ().chomp () == "" || sentence.replace ("*", "").chug ().chomp () == "")
{
return true;
}
var sent = new Sentence (check_sentence, dictionary);
sent.split (options);
var num_linkages = sent.parse (options);
// Only highlight issues if links were established
if (num_linkages > 0) {
var linkage = new Linkage (0, sent, options);
string raw_suggestion = "";
var num_words = linkage.get_num_words ();
// Find the failed links
for (size_t w = 0; w < num_words; w++) {
string word = linkage.get_word (w);
if (word.has_prefix ("[")) {
error_free = false;
}
raw_suggestion += word + " ";
}
parse_suggestion (raw_suggestion, out suggestion, problem_words);
}
return error_free;
}
The Linkage returns something like:
+-----------------------Xp----------------------+
+-------->WV-------->+ |
+---->Wd-----+ | |
| +Ds**c+--Ss*s-+--------Os--------+ +--RW--+
| | | | | | |
LEFT-WALL the side.n affects.v [were] devastating.g . RIGHT-WALL
We parse each word to find the failed [links] and put them into a list to highlight.
A call to sentence_check_ex ("The side affects were devastating", out suggestion, problem_words) will provide:
suggestion = "the side affects [were] devastating"
problem_words = ["were"]
Using this, we can grab sentences from a Gtk.TextView and then highlight them.
When I first tried this, I connected grammar checking to Gtk.TextBuffer's changed signal. Every keystroke would lock the GUI while grammar checking occurred.
To prevent this, we need multi-threading or good coordination of the main loop.
I have a math degree and never studied design patterns. I like to think we're about to use the Producer Consumer design pattern.
Vala provides a Concurrent Set. We can use this to coordinate getting link-grammar suggestions and displaying the suggestions. First, we need a way to communicate.
public class GrammarUpdateRequest : Object {
// Original text from the buffer
public string text;
// Words to highlight as problematic
public Gee.List<string> words;
public GrammarUpdateRequest () {
words = new Gee.LinkedList<string> ();
}
public static int compare_tag_requests (GrammarUpdateRequest a, GrammarUpdateRequest b) {
return strcmp (a.text, b.text);
}
}
Inside our Gtk.TextView grammar checker, we can create 2 sets.
public class GrammarChecker : Object {
// Threading State
private Thread<void> grammar_processor;
private Gee.ConcurrentSet<GrammarUpdateRequest> send_to_processor;
private Gee.ConcurrentSet<GrammarUpdateRequest> send_to_buffer;
public GrammarChecker () {
/* ... */
send_to_processor = new Gee.ConcurrentSet<GrammarUpdateRequest> (GrammarUpdateRequest.compare_tag_requests);
send_to_buffer = new Gee.ConcurrentSet<GrammarUpdateRequest> (GrammarUpdateRequest.compare_tag_requests);
}
send_to_processor handles sending sentences to link-grammar. send_to_buffer handles updating the TextView.
Shout out to the minds behind TextBuffer and TextIter. We get forward_sentence_end and backward_sentence_start.
Given start and end TextIter's, we can find all the sentences to parse.
private void run_worker_between_start_and_end (Gtk.TextIter start, Gtk.TextIter end) {
// Okay, we lied. Try to make sure the start starts at the start of a sentence
if (!start.starts_sentence ()) {
start.backward_sentence_start ();
}
// We move backward because forward could grab more lines
if (!end.ends_sentence ()) {
end.backward_sentence_start ();
}
// Make sure we have something to grab
if (end.get_offset () == start.get_offset ()) {
return;
}
// Remove previous grammar tags between scan area
buffer.remove_tag (grammar_line, start, end);
buffer.remove_tag (grammar_word, start, end);
// Grab the first sentence and move the end iterator
Gtk.TextIter check_end = start;
grab_sentence (ref start, ref check_end);
Gtk.TextIter check_start = start;
// Where something not quite as magical happens...
// loop over every sentence in range.
while (check_start.in_range (start, end) &&
check_end.in_range (start, end) &&
(check_end.get_offset () != check_start.get_offset ()))
{
Gtk.TextIter cursor_iter;
var cursor = buffer.get_insert ();
buffer.get_iter_at_mark (out cursor_iter, cursor);
// If the cursor is in the sentence, don't tell the user their possibly
// incomplete sentence is grammatically incorrect. It's in progress, mmkay?
if (!cursor_iter.in_range (check_start, check_end))
{
// Grab the sentence and prep for problem word tagging
string sentence = buffer.get_text (check_start, check_end, false).chug ().chomp ();
// Only run on full sentences
if (sentence != "" && sentence.index_of_char (' ') != -1) {
GrammarUpdateRequest request = new GrammarUpdateRequest () {
text = sentence
};
send_to_processor.add (request);
}
}
// Move along to the next sentence (if possible)
check_start = check_end;
check_start.forward_char ();
if (!check_end.forward_sentence_end ()) {
break;
}
grab_sentence (ref check_start, ref check_end);
}
start_worker ();
}
//
// Where the magic happens
//
private void grab_sentence (ref Gtk.TextIter start, ref Gtk.TextIter end) {
//
// Check if we're tagging markdown links and URLs
//
var link_tag = buffer.tag_table.lookup ("markdown-link");
var url_tag = buffer.tag_table.lookup ("markdown-url");
//
// Gtk.TextIter determines .end_sentence () based on punctuation. "twirp.in"
// would cause "twirp" to be detected as the end of sentence. But, we're in a URL
// So continue on down, and check for end_sentence not in a URL.
//
if (link_tag != null && url_tag != null) {
if (!end.ends_sentence () || ((link_tag != null && end.has_tag (link_tag)) || (url_tag != null && end.has_tag (url_tag)))) {
do {
Gtk.TextIter next_line = end.copy (), next_sentence = end.copy ();
if (next_line.forward_to_line_end () && next_sentence.forward_sentence_end () && next_line.get_offset () < next_sentence.get_offset ()) {
end.forward_to_line_end ();
break;
}
if (!end.forward_sentence_end ()) {
break;
}
} while ((end.has_tag (url_tag) || end.has_tag (link_tag)));
}
}
}
This code runs over the buffer between the provided TextIter's to queue all sentences. grab_sentence does some additional magic. We have a Markdown Helper tagging links and other markdown.
Our start_worker code looks like:
// Threading State
private Thread<void> grammar_processor;
private bool processor_running;
private Mutex processor_check;
// Check if worker queue is already running. If not,
// starts the worker thread.
private void start_worker () {
processor_check.lock ();
if (!processor_running) {
if (grammar_processor != null) {
grammar_processor.join ();
}
processor_running = true;
grammar_processor = new Thread<void> ("grammar-processor", process_grammar);
GLib.Idle.add (update_buffer);
}
processor_check.unlock ();
}
A Mutex is a lock. In this case, we're locking the processor_running boolean and making sure we only have one grammar-processor thread running.
The grammar processing code dequeues sentences from the queue, checks their grammar, and queues the suggestions.
private void process_grammar () {
while (send_to_processor.size != 0) {
// Dequeue sentence to process
GrammarUpdateRequest requested = send_to_processor.first ();
send_to_processor.remove (requested);
string sentence = strip_markdown (requested.text).chug ().chomp ();
// Run grammar check and enqueue if issue found
if (!checker.sentence_check (sentence, requested.words)) {
send_to_buffer.add (requested);
}
}
// Terminate thread since there's no more work to do
processor_running = false;
Thread.exit (0);
return;
}
In our start_worker code, we had a link GLib.Idle.add (update_buffer);. This will run our update_buffer code at a low priority.
// Processes the queue to update the buffer if the sentence
// still matches.
private bool update_buffer () {
Gtk.TextIter buffer_start, buffer_end, cursor_location;
var cursor = buffer.get_insert ();
buffer.get_iter_at_mark (out cursor_location, cursor);
buffer.get_bounds (out buffer_start, out buffer_end);
// Grab contents to find sentence to highlight
string buffer_text = buffer.get_text (buffer_start, buffer_end, true);
while (send_to_buffer.size != 0) {
// Dequeue item
GrammarUpdateRequest requested = send_to_buffer.first ();
send_to_buffer.remove (requested);
// Find the offset of the sentence to highlight
int start_pos = buffer_text.index_of (requested.text);
while (start_pos >= 0) {
// Use character count to handle emoji/unicode
int char_pos = buffer_text.char_count (start_pos);
int end_char_pos = char_pos + requested.text.char_count ();
// Check at the offset in the request
Gtk.TextIter check_start, check_end;
buffer.get_iter_at_offset (out check_start, char_pos);
buffer.get_iter_at_offset (out check_end, end_char_pos);
if (check_start.in_range (buffer_start, buffer_end) &&
check_end.in_range (buffer_start, buffer_end) &&
check_start.get_text (check_end).chug ().chomp () == requested.text)
{
tag_sentence (check_start, check_end, requested.words);
}
start_pos = buffer_text.index_of (requested.text, start_pos + 1);
}
}
return processor_running;
}
private void tag_sentence (Gtk.TextIter check_start, Gtk.TextIter check_end, Gee.List<string> problem_words) {
// Skip markdown characters
while (check_start.get_char () == ' ' || check_start.get_char () == '#' ||
check_start.get_char () == '-' || check_start.get_char () == '*' ||
check_start.get_char () == '>')
{
if (!check_start.forward_char ()) {
break;
}
}
// Display error line
buffer.apply_tag (grammar_line, check_start, check_end);
Gtk.TextIter word_start = check_start.copy ();
Gtk.TextIter word_end = check_start.copy ();
// If we have words we can highlight, highlight them.
// Sadly note: we do not highlight punctuation, we also highlight
// multiple occurrences of a matchin word even though one instance
// may be incorrect
if (!problem_words.is_empty) {
while (word_end.forward_word_end () && word_end.get_offset () <= check_end.get_offset ()) {
// Grab the word in the sentence and try to make it as basic as possible
string check_word = strip_markdown (word_start.get_text (word_end)).chug ().chomp ();
check_word = check_word.replace ("\"", "");
// Check if the word is in the list of problematic words
if (problem_words.contains (check_word) || // what's coding style?
problem_words.contains (check_word.down ()))
{
// Strip whitespace in iter
while (word_start.get_char () == ' ' || word_start.get_char () == '#' ||
word_start.get_char () == '>' || word_start.get_char () == '-')
{
if (!word_start.forward_char ())
{
break;
}
}
buffer.apply_tag (grammar_word, word_start, word_end);
}
word_start = word_end;
}
}
}
We can run this as part of our main loop because it's not resource intensive. The heavy lifting was done in the grammar checking thread. This code swipes its highlighter.
All of these operations are performed on a TextView. Now we can write our code to attach.
private static GrammarThinking? checker;
private static Mutex checker_init = Mutex ();
public bool attach (Gtk.TextView textview) {
view = textview;
buffer = textview.get_buffer ();
// Create text tags and define formatting
grammar_line = buffer.create_tag ("grammar_check", "underline", Pango.Underline.ERROR, null);
grammar_line.underline_rgba = Gdk.RGBA () { red = 0.0f, green = 0.40f, blue = 0.133f, alpha = 1.0f };
grammar_word = buffer.create_tag ("grammar_word", "underline", Pango.Underline.ERROR, null);
grammar_word.underline_rgba = Gdk.RGBA () { red = 0.0f, green = 0.40f, blue = 0.133f, alpha = 1.0f };
grammar_word.background_rgba = Gdk.RGBA () { red = 0.0f, green = 0.40f, blue = 0.133f, alpha = 1.0f };
grammar_word.foreground_rgba = Gdk.RGBA () { red = 0.9f, green = 0.9f, blue = 0.9f, alpha = 1.0f };
grammar_word.background_set = true;
grammar_word.foreground_set = true;
// Create single instance of grammar checker
if (checker == null) {
checker_init.lock ();
if (checker == null) {
checker = new GrammarThinking ();
}
checker_init.unlock ();
}
view.set_has_tooltip (true);
view.query_tooltip.connect (handle_tooltip);
last_cursor = -1; // reset to scan whole document on attach
GLib.Idle.add (update_buffer);
return true;
}
public bool handle_tooltip (int x, int y, bool keyboard_tooltip, Gtk.Tooltip tooltip) {
if (buffer == null) {
return false;
}
Gtk.TextIter? iter;
// Determine if user requested a tooltip via mouse or keyboard
if (keyboard_tooltip) {
int offset = buffer.cursor_position;
buffer.get_iter_at_offset (out iter, offset);
} else {
int m_x, m_y, trailing;
view.window_to_buffer_coords (Gtk.TextWindowType.TEXT, x, y, out m_x, out m_y);
view.get_iter_at_position (out iter, out trailing, m_x, m_y);
}
if (iter != null) {
if (iter.has_tag (grammar_line)) {
// Find the sentence the user is hovered over or in
Gtk.TextIter start = iter.copy (), end = iter.copy ();
bool no_foward = false;
while (start.has_tag (grammar_line)) {
if (!start.backward_char ()) {
no_foward = true;
break;
}
}
if (!no_foward) {
start.forward_char ();
}
no_foward = false;
while (end.has_tag (grammar_line)) {
if (!end.forward_char ()) {
no_foward = true;
break;
}
}
if (!no_foward) { // lol, variable reuse
end.backward_char ();
}
string suggestion = "";
// Run the checker over the sentence to and show raw suggestion output
if (!checker.sentence_check_suggestion (strip_markdown (buffer.get_text (start, end, false)), out suggestion) && suggestion != "") {
tooltip.set_markup (suggestion.replace ("&", "&").replace ("<", "<"). replace (">", ">"));
return true; // Don't try to find other tooltips
}
}
} else {
return false; // I got nothing for you, see if someone else has a tooltip
}
return false;
}
This code handles attaching to the text view and also defines a tool-tip for showing the issues.
We're almost done with our Gtk.TextView grammar checking enrichment. We need to provide a way to scan the buffer.
// Timer between when checks can run
private TimedMutex limit_updates;
// Mutex to prevent multiple scans at same time
private Mutex checking;
public void recheck_all () {
// Limit how frequently grammar checking can run
if (!limit_updates.can_do_action ()) {
return;
}
// Check if grammar checking is already running
if (!checking.trylock ()) {
return;
}
Gtk.TextIter t_start, t_end;
buffer.get_bounds (out t_start, out t_end);
run_worker_between_start_and_end (t_start, t_end);
// Release lock
checking.unlock ();
}
This code does some rate limiting for updates. If we've checked too recently, we skip. If grammar checking is already running, we bail.
Our TimedMutex looks something like:
public class TimedMutex {
private bool can_action;
private Mutex droptex;
private int delay;
/**
* Constructs a TimedMutex object, defaults to 1.5 seconds
*
* @param milliseconds_delay Amount of time to hold lock before releasing
*/
public TimedMutex (int milliseconds_delay = 1500) {
if (milliseconds_delay < 100) {
milliseconds_delay = 100;
}
delay = milliseconds_delay;
can_action = true;
droptex = Mutex ();
}
/**
* Returns true if enough time has ellapsed since the last call.
* Returns false if action should not be taken.
*/
public bool can_do_action () {
bool res = false;
if (droptex.trylock()) {
if (can_action) {
res = true;
can_action = false;
}
Timeout.add (delay, clear_action);
droptex.unlock ();
}
return res;
}
private bool clear_action () {
droptex.lock ();
can_action = true;
droptex.unlock ();
return false;
}
}
This Mutex will remain locked for 1.5 seconds by default. After 1.5 seconds, the lock is released.
Now we have a grammar checker and a Gtk.TextView add-on. Let's put it all together.
All this code, and we haven't even created a TextView yet. For this example, we're using GtkSourceView5 as our TextView. This will provide Markdown syntax highlighting.
public class GrammarCheck : Gtk.Application {
private GtkSource.View source_view;
private GtkSource.Buffer source_buffer;
private Markdown markdown_enrichment;
private GrammarChecker grammar_enrichment;
protected override void activate () {
// Grab application Window
var window = new Gtk.ApplicationWindow (this);
window.set_title ("GrammarChecker");
window.set_default_size (600, 320);
// Scroll view to hold contents
var scroll_box = new Gtk.ScrolledWindow ();
// Get a pointer to the Markdown Language
var manager = GtkSource.LanguageManager.get_default ();
var language = manager.guess_language (null, "text/markdown");
// Create a GtkSourceView and create a markdown buffer
source_view = new GtkSource.View ();
source_buffer = new GtkSource.Buffer.with_language (language);
source_buffer.highlight_syntax = true;
source_view.set_buffer (source_buffer);
source_view.set_wrap_mode (Gtk.WrapMode.WORD);
// Set placeholder text
source_buffer.text = "# Hello DEV!\n\nYou can type away.\n";
// Add the GtkSourceView to the Scroll Box
scroll_box.set_child (source_view);
// Attack grammar checker
grammar_enrichment = new GrammarChecker ();
grammar_enrichment.attach (source_view);
// Run grammar checking 1/4 of a second after application start
Timeout.add (250, () => {
grammar_enrichment.recheck_all ();
return false;
});
// Sign up for buffer updates
source_buffer.changed.connect (() => {
grammar_enrichment.recheck_all ();
});
window_removed.connect (() => {
grammar_enrichment.detach ();
});
// Populate the Window
window.child = scroll_box;
window.present ();
}
public static int main (string[] args) {
return new GrammarCheck ().run (args);
}
}

This code creates our TextView, attaches our grammar checker, and runs the grammar checker when the buffer changes.
The full code can be found at github.com/TwiRp/gtk4-textview-grammar.
We may have abandoned the word processor, but we don't have to abandon our humanity.
The code in the repo does some additional magic. We keep track of the cursor location. Grammar checking is done around the active cursor location and the 'last known' cursor location.